
Introduction
Vision-Language Models (VLMs) are rapidly becoming the core of many generative AI applications, from multimodal chatbots and agentic systems to automated content analysis tools. As open-source models mature, they offer promising alternatives to proprietary systems, enabling developers and enterprises to build cost-effective, scalable, and customizable AI solutions.
However, the growing number of VLMs presents a common dilemma: how do you choose the right model for your use case? It’s often a balancing act between output quality, latency, throughput, context length, and infrastructure cost.
This blog aims to simplify the decision-making process by providing detailed benchmarks and model descriptions for three leading open-source VLMs: Gemma-3-4B, MiniCPM-o 2.6, and Qwen2.5-VL-7B-Instruct. All benchmarks were run using Clarifai’s Compute Orchestration, our own inference engine, to ensure consistent conditions and reliable comparisons across models.
Before diving into the results, here’s a quick breakdown of the key metrics used in the benchmarks. All results were generated using Clarifai’s Compute Orchestration on NVIDIA L40S GPUs, with input tokens set to 500 and output tokens set to 150.
- Latency per Token: The time it takes to generate each output token. Lower latency means faster responses, especially important for chat-like experiences.
- Time to First Token (TTFT): Measures how quickly the model generates the first token after receiving the input. It impacts perceived responsiveness in streaming generation tasks.
- End-to-End Throughput: The number of tokens the model can generate per second for a single request, considering the full request processing time. Higher end-to-end throughput means the model can efficiently generate output while keeping latency low.
-
Overall Throughput: The total number of tokens generated per second across all concurrent requests. This reflects the model’s ability to scale and maintain performance under load.
Now, let’s dive into the details of each model, starting with Gemma-3-4B.
Gemma3-4b
Gemma-3-4B, part of Google’s latest Gemma 3 family of open multimodal models, is designed to handle both text and image inputs, producing coherent and contextually rich text responses. With support for up to 128K context tokens, 140+ languages, and tasks like text generation, image understanding, reasoning, and summarization, it’s built for production-grade applications across diverse use cases.
Benchmark Summary: Performance on L40S GPU
Gemma-3-4B continues to show strong performance across both text and image tasks, with consistent behavior under varying concurrency levels. All benchmarks were run using Clarifai’s Compute Orchestration with input size of 500 tokens and output size of 150 tokens. Gemma-3-4B is optimized for low-latency text processing and handles image inputs up to 512px with stable throughput across concurrency levels.
Text-Only Performance Highlights:
-
Latency per token: 0.022 sec (1 concurrent request)
-
Time to First Token (TTFT): 0.135 sec
-
End-to-end throughput: 202.25 tokens/sec
-
Requests per minute (RPM): Up to 329.90 at 32 concurrent requests
-
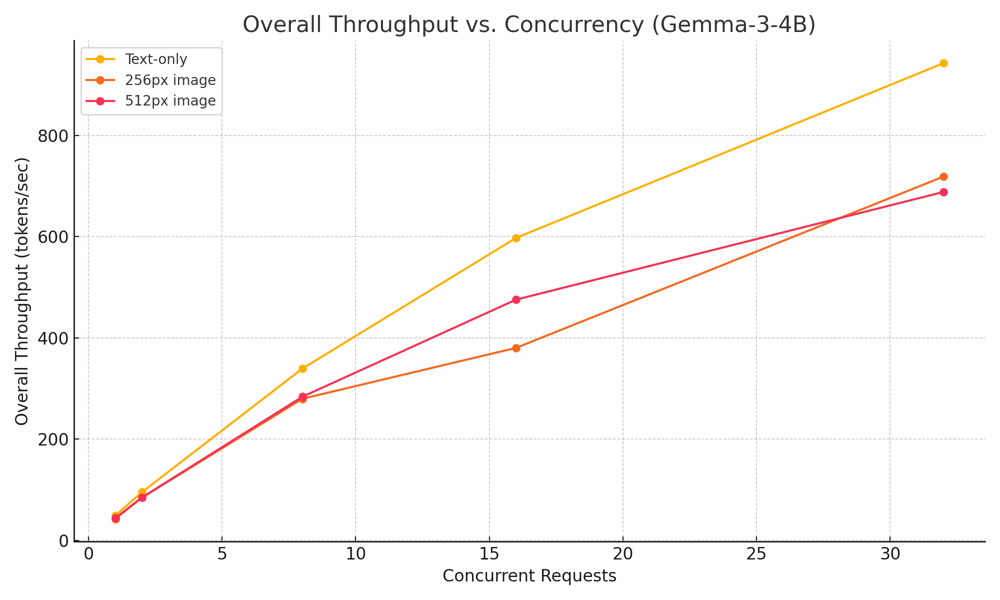
Overall throughput: 942.57 tokens/sec at 32 concurrency
Multimodal (Image + Text) Performance (Overall Throughput):
-
256px images: 718.63 tokens/sec, 252.16 RPM at 32 concurrency
-
512px images: 688.21 tokens/sec, 242.04 RPM
Scales with Concurrency (End-to-End Throughput):
-
At 2 concurrent requests:
-
At 8 concurrent requests:
-
At 16 concurrent requests:
-
At 32 concurrent requests:
Overall Insight:
Gemma-3-4B provides fast and reliable performance for text-heavy and structured vision-language tasks. For large image inputs (512px), performance remains stable, but you may need to scale compute resources to maintain low latency and high throughput.
If you’re evaluating GPU performance for serving this model, we’ve published a separate comparison of A10 vs. L40S, helping you choose the best hardware for your needs.
MiniCPM-o 2.6
MiniCPM-o 2.6 represents a major leap in end-side multimodal LLMs. It expands input modalities to images, video, audio, and text, offering real-time speech conversation and multimodal streaming support.
With an architecture integrating SigLip-400M, Whisper-medium-300M, ChatTTS-200M, and Qwen2.5-7B, the model boasts a total of 8 billion parameters. MiniCPM-o-2.6 demonstrates significant improvements over its predecessor, MiniCPM-V 2.6, and introduces real-time speech conversation, multimodal live streaming, and superior efficiency in token processing.
Benchmark Summary: Performance on L40S GPU
All benchmarks were run using Clarifai’s Compute Orchestration with input size of 500 tokens and output size of 150 tokens. MiniCPM-o-2.6 performs exceptionally well across both text and image workloads, scaling smoothly across concurrency levels. Shared vLLM serving provides significant gains in overall throughput while maintaining low latency.
Text-Only Performance Highlights:
-
Latency per token: 0.022 sec (1 concurrent request)
-
Time to First Token (TTFT): 0.087 sec
-
End-to-end throughput: 213.23 tokens/sec
-
Requests per minute (RPM): Up to 362.83 at 32 concurrent requests
-
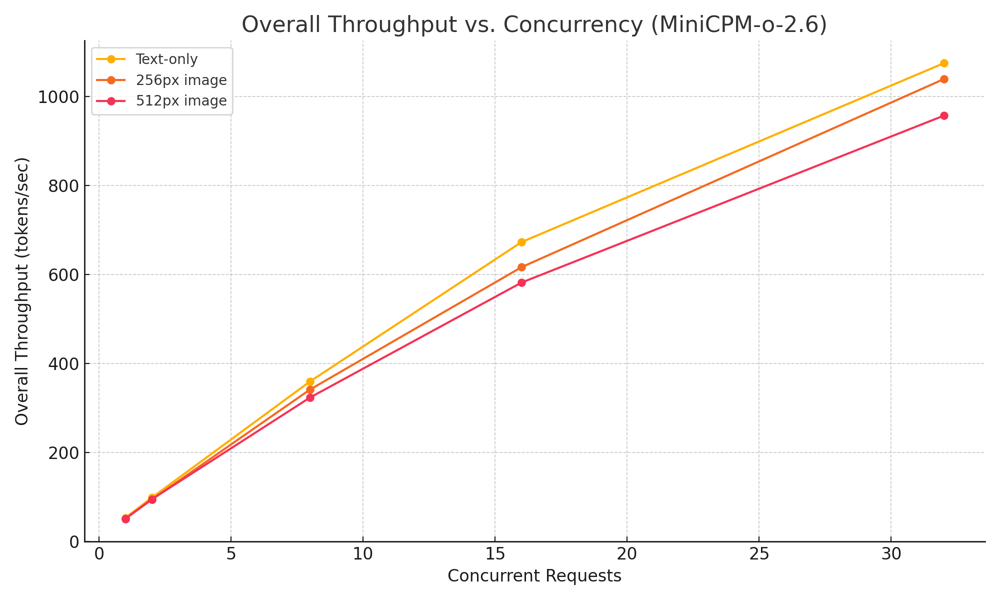
Overall throughput: 1075.28 tokens/sec at 32 concurrency
Multimodal (Image + Text) Performance (Overall Throughput):
-
256px images: 1039.60 tokens/sec, 353.19 RPM at 32 concurrency
-
512px images: 957.37 tokens/sec, 324.66 RPM
Scales with Concurrency (End-to-End Throughput):
-
At 2 concurrent requests:
-
At 8 concurrent requests:
-
At 16 concurrent requests:
-
At 32 concurrent requests:
Overall Insight:
MiniCPM-o-2.6 performs reliably across a range of tasks and input sizes. It maintains low latency, scales linearly with concurrency, and remains performant even with 512px image inputs. This makes it a solid choice for real-time applications running on modern GPUs like the L40S. These results reflect performance on that specific hardware configuration, and may vary depending on the environment or GPU tier.
Qwen2.5-VL-7B-Instruct
Qwen2.5-VL is a vision-language model designed for visual recognition, reasoning, long video analysis, object localization, and structured data extraction.
Its architecture integrates window attention into the Vision Transformer (ViT), significantly improving both training and inference efficiency. Additional optimizations like SwiGLU activation and RMSNorm further align the ViT with the Qwen2.5 LLM, enhancing overall performance and consistency.
Benchmark Summary: Performance on L40S GPU
Qwen2.5-VL-7B-Instruct delivers consistent performance across both text and image-based tasks. Benchmarks from Clarifai’s Compute Orchestration highlight its ability to handle multimodal inputs at scale, with strong throughput and responsiveness under varying concurrency levels.
Text-Only Performance Highlights:
-
Latency per token: 0.022 sec (1 concurrent request)
-
Time to First Token (TTFT): 0.089 sec
-
End-to-end throughput: 205.67 tokens/sec
-
Requests per minute (RPM): Up to 353.78 at 32 concurrent requests
-
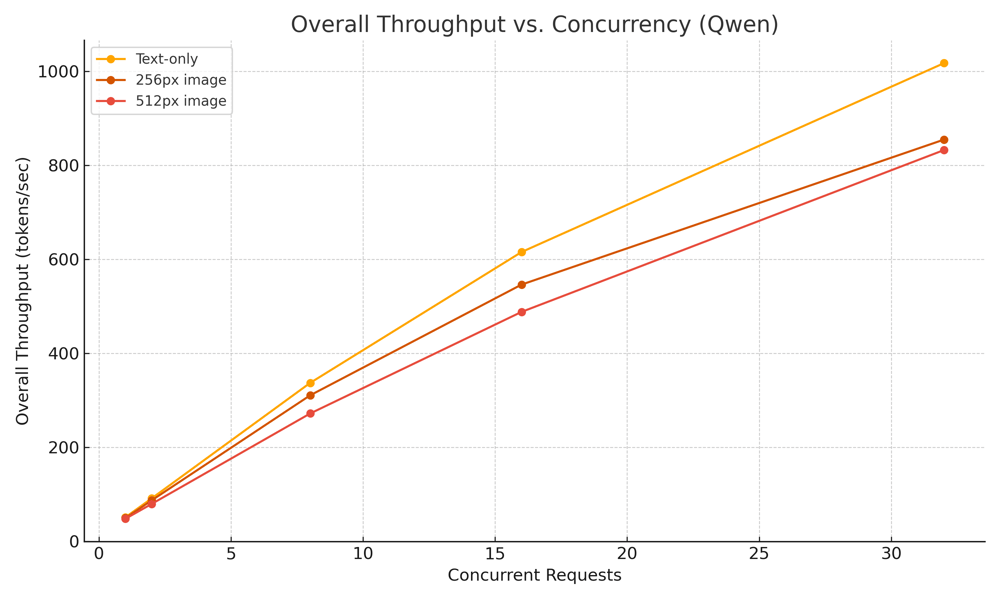
Overall throughput: 1017.16 tokens/sec at 32 concurrency
Multimodal (Image + Text) Performance (Overall Throughput):
-
256px images: 854.53 tokens/sec, 318.64 RPM at 32 concurrency
-
512px images: 832.28 tokens/sec, 345.98 RPM
Scales with Concurrency (End-to-End Throughput):
-
At 2 concurrent requests:
-
At 8 concurrent requests:
-
At 16 concurrent requests:
-
At 32 concurrent requests:
Overall Insight:
Qwen2.5-VL-7B-Instruct is well-suited for both text and multimodal tasks. While larger images introduce latency and throughput trade-offs, the model performs reliably with small to medium-sized inputs even at high concurrency. It’s a strong choice for scalable vision-language pipelines that prioritize throughput and moderate latency.
Which VLM is Right for You?
Choosing the right Vision-Language Model (VLM) depends on your workload type, input modality, and concurrency requirements. All benchmarks in this report were generated using NVIDIA L40S GPUs via Clarifai’s Compute Orchestration.
These results reflect performance on enterprise-grade infrastructure. If you’re using lower-end hardware or targeting larger batch sizes or ultra-low latency, actual performance may differ. It’s important to evaluate based on your specific deployment setup.
MiniCPM-o-2.6
MiniCPM offers consistent performance across both text and image tasks, especially when deployed with shared vLLM. It scales efficiently up to 32 concurrent requests, maintaining high throughput and low latency even with 1024px image inputs.
If your application requires stable performance under load and flexibility across modalities, MiniCPM is the most well-rounded choice in this group.
Gemma-3-4B
Gemma performs best on text-heavy workloads with occasional image input. It handles concurrency well up to 16 requests but begins to dip at 32, particularly with large images such as 2048px.
If your use case is primarily focused on fast, high-quality text generation with small to medium image inputs, Gemma provides strong performance without needing high-end scaling.
Qwen2.5-VL-7B-Instruct
Qwen2.5 is optimized for structured vision-language tasks such as document parsing, OCR, and multimodal reasoning, making it a strong choice for applications that require precise visual and textual understanding.
If your priority is accurate visual reasoning and multimodal understanding, Qwen2.5 is a strong fit, especially when output quality matters more than peak throughput.
To help you compare at a glance, here’s a summary of the key performance metrics for all three models at 32 concurrent requests across text and image inputs.
Vision-Language Model Benchmark Summary (32 Concurrent Requests, L40S GPU)
| Metric | Model | Text Only | 256px Image | 512px Image |
|---|---|---|---|---|
| Latency per Token (sec) | Gemma-3-4B | 0.027 | 0.036 | 0.037 |
| MiniCPM-o 2.6 | 0.024 | 0.026 | 0.028 | |
| Qwen2.5-VL-7B-Instruct | 0.025 | 0.032 | 0.032 | |
| Time to First Token (sec) | Gemma-3-4B | 0.236 | 1.034 | 1.164 |
| MiniCPM-o 2.6 | 0.120 | 0.347 | 0.786 | |
| Qwen2.5-VL-7B-Instruct | 0.121 | 0.364 | 0.341 | |
| End-to-End Throughput (tokens/s) | Gemma-3-4B | 168.45 | 124.56 | 120.01 |
| MiniCPM-o 2.6 | 188.86 | 176.29 | 160.14 | |
| Qwen2.5-VL-7B-Instruct | 186.91 | 179.69 | 191.94 | |
| Overall Throughput (tokens/s) | Gemma-3-4B | 942.58 | 718.63 | 688.21 |
| MiniCPM-o 2.6 | 1075.28 | 1039.60 | 957.37 | |
| Qwen2.5-VL-7B-Instruct | 1017.16 | 854.53 | 832.28 | |
| Requests per Minute (RPM) | Gemma-3-4B | 329.90 | 252.16 | 242.04 |
| MiniCPM-o 2.6 | 362.84 | 353.19 | 324.66 | |
| Qwen2.5-VL-7B-Instruct | 353.78 | 318.64 | 345.98 |
Note: These benchmarks were run on L40S GPUs. Results may vary depending on GPU class (such as A100 or H100), CPU limitations, or runtime configurations including batching, quantization, or model variants.
Conclusion
We have seen the benchmarks across MiniCPM-2.6, Gemma-3-4B, and Qwen2.5-VL-7B-Instruct, covering their performance on latency, throughput, and scalability under different concurrency levels and image sizes. Each model performs differently based on the task and workload requirements.
If you want to try out these models, we have launched a new AI Playground where you can explore them directly. We will continue adding the latest models to the platform, so keep an eye on our updates and join our Discord community for the latest announcements.
If you are also looking to deploy these Open Source VLMs on your own dedicated compute, our platform supports production-grade inference, and scalable deployments. You can quickly get started with setting up your own node pool and running inference efficiently. Check out the tutorial below to get started.



