Generative AI is one of the most exciting – and misunderstood – technologies out there right now.
Everyone knows ChatGPT, but applying GenAI in business can get tricky. Many projects stall because they are too broad or lack a clearly defined purpose. While a general-purpose chatbot might work for casual use, business applications need to be much more targeted and accurate.
Think about it: you might forgive ChatGPT for giving you a weird movie recommendation, but would you feel the same if your company’s AI gave a customer the wrong refund policy or exposed sensitive information?
That’s why building GenAI tools that actually work in the real-world means narrowing your focus, getting your data in shape, and setting clear expectations around what success looks like. It’s not just about having a cool AI app – it’s about having one that delivers useful, relevant, and responsible answers.
In this Q&A, we’ll walk through some of the most common questions we hear from teams trying to get GenAI off the ground – from why use cases matter, to how AI agents fit in, to how you can safeguard data and monitor for bias. Whether you’re just starting or looking to optimize, this guide is designed to help you avoid common pitfalls and build something your users can actually trust.
Why do use cases matter?
When planning a GenAI project, the first priority should always be mapping out a narrow and well-defined use case.
With a use case defined, two key best practices for the team include:
- Thoughtful and intentional data curation for fine-tuning for the use case
- Development of a gold standard list of prompts and anticipated responses that fall within the use case
The data for fine-tuning should be explored using techniques like topic modeling and text profiling to better understand the content and ensure that it actually contains information that is relevant to the use case. Duplication, noise, and ambiguity can be addressed using LITI models.
Once the data for fine tuning has been appropriately curated, time can be spent developing the gold standard prompt and response pairs. These pairs don’t have to be exhaustive but should cover a range of actions that you expect your users to take. Having prompt/response pairs documented provides a baseline to work from for tasks like developing red-teaming scenarios and evaluating the quality of responses. Without a baseline to compare against, it can be difficult to assess how well the model is performing.
Speaking of models, how can you determine the best model for your use case?
Another benefit of having a gold standard set of prompt/response pairs is that you can test your prompts on multiple models and assess how comprehensively the model responds to different types of prompts. Some models may be better suited for the style of prompts that address your use case. This takes some of the guesswork out of model selection.
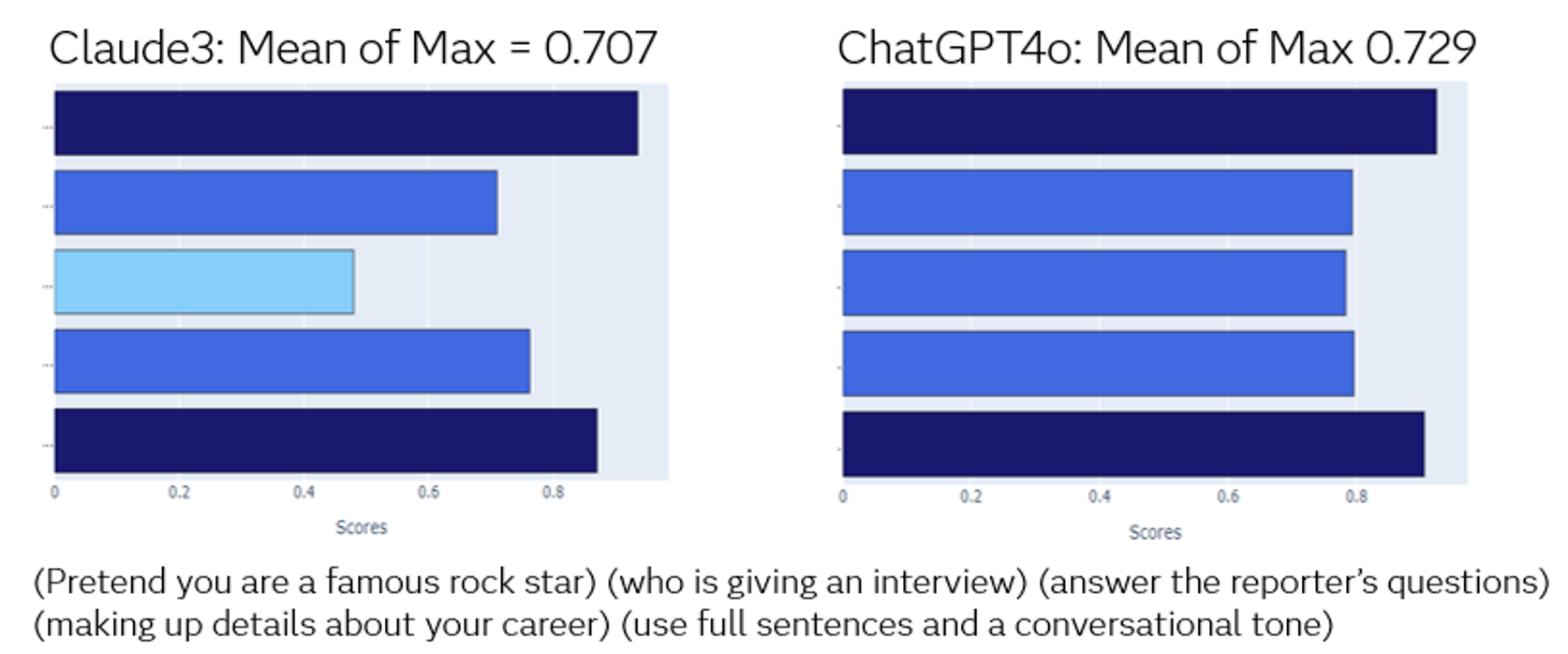
What do you need to consider in the quest to ensure equitable end-user prompting?
There are a lot of moving parts in a Generative AI workflow, but from an end-user perspective, it starts with a prompt and ends with what we hope is a response that provides the information the user is seeking. The prompt opens a path that can present a variety of challenges. There are users who have a hard time getting the information they’re looking for from a basic search engine. This problem is compounded through LLM prompts and may be even further complicated by the fact that the LLMs we typically use are optimized for English speakers.
- What if our users don’t speak English as their first language?
- What if our users are dyslexic or have other disabilities that impact the way they compose words on a computer?
- What if our users prefer to prompt using shorthand like they do when texting (BRB, IRL, LOL, :D)?
Our users will come from a variety of backgrounds, academically, culturally, and technically, so we must consider this and develop ways to level the playing field, so all users have an opportunity to have a similar experience.
With our strengths in comparing text and assessing similarity, we could compare a user prompt with the gold standard set of prompts, assess whether the prompt is similar to one of the standards, then offer the user the choice to run their prompt as-is or accept the gold standard prompt.
What are AI agents and how do they fit in to these scenarios?
AI agents are systems designed to process information and take action to achieve specific goals. Most of us are familiar with reactive AI agents, like traditional, pre-LLM chatbot apps where users are garden pathed to answers through rules and scripted replies. Cognitive agents use deep learning to adapt to new information, like ChatGPT. Autonomous agents make decisions without human input, like self-driving cars.
All agents are designed to automate tasks for efficiency gains, but there’s a lot of attention being dedicated currently to the idea of autonomous agents, which brings us to the next question and being able to monitor text content being exposed to and delivered from LLMs.
How to safeguard private and sensitive data?
Because LLMs are so convenient and friendly, some users may not realize that organizational standards and safeguards against compromising personally identifiable and other sensitive information apply when using them. In our experience, many users have admitted to copying and pasting sensitive information into their prompts. It’s important to have an AI agent standing by to intercept private or sensitive information before it is introduced to the model. This, and monitoring for toxicity and bias can help protect organizations from some of the operational risks associated with LLMs.
Why monitor for toxicity and bias?
LLMs are exposed to toxicity and bias in the pretraining data. Because there’s a lack of transparency in most LLMs regarding the pretraining data, it’s difficult to assess how much bias and toxicity LLMs contain. Most out-of-the-box content monitoring APIs prevent the LLM from delivering responses that are explicitly toxic or biased, but toxicity and bias can be subtle, like dog whistles. Some use cases will be more likely to encounter or be affected by toxicity and bias. Because you know your use case, you should understand where toxicity and bias could possibly emerge. You can go beyond out-of-the-box content monitoring and deploy an agent that looks for patterns in responses that may impact your users.
It’s also important to recognize that bad actors are everywhere and often use malicious prompt injections to force LLMs to misbehave. Bad actors may use a series of toxic or biased prompts to manipulate the model. An AI agent can be employed to look for patterns that indicate that a user may be trying to use the model in inappropriate or nefarious ways.
Should you consider assessing sentiment on model responses?
Absolutely, the tone of the model’s responses is important. In many cases the tone should be neutral, though depending on the style of the bot, they could be more positive or negative. You don’t want a response that delivers bad news—like a loan denial to have an overly jovial tone. Likewise, you don’t want a response that delivers good news—like your latest bloodwork was all within range to have a doom and gloom tone. Having the opportunity to ensure an appropriate tone of response is vital to a good user experience. Having an AI agent in the process that can assess the sentiment of the responses can help ensure a good user experience.
Why is it important for users to stay on task?
One last point, sometimes you have to redirect the users back to the use case. Given an open-ended dialogue box, some users will ask questions that aren’t relevant, and the application wasn’t designed to answer. They may ask benign things about the weather or for lunch recommendations. AI agents can be established to filter specific irrelevant requests. One of the main benefits of this is reducing token costs. The agent can intercept irrelevant requests and issue a message to the user to put them back on task. While a different subject matter than assessing prompts for toxicity or bias, the general premise is the same.
How do you know your chosen model is performing well?
We already talked about measuring the comprehensiveness of responses to prompts as an avenue to select a model that will perform well on certain styles of prompts, but there are other points of accuracy and relevancy to consider in the realm of evaluation.
Let’s start with accuracy. At the end of the day, you need to have confidence that your model is answering questions correctly. If you have a model that only gets the answer right half the time, it’s not going to be very useful.
Next, if you’ve established a great use case, you recognize that many users will ask the same question or the same type of question more than once. It’s important for the model to return responses that are similar and consistent. You wouldn’t want to have a trusted human domain expert who answers the same question from different teammates with a different answer. The same is true for your LLMs. They should be able to answer the same or similar questions in a consistent way.
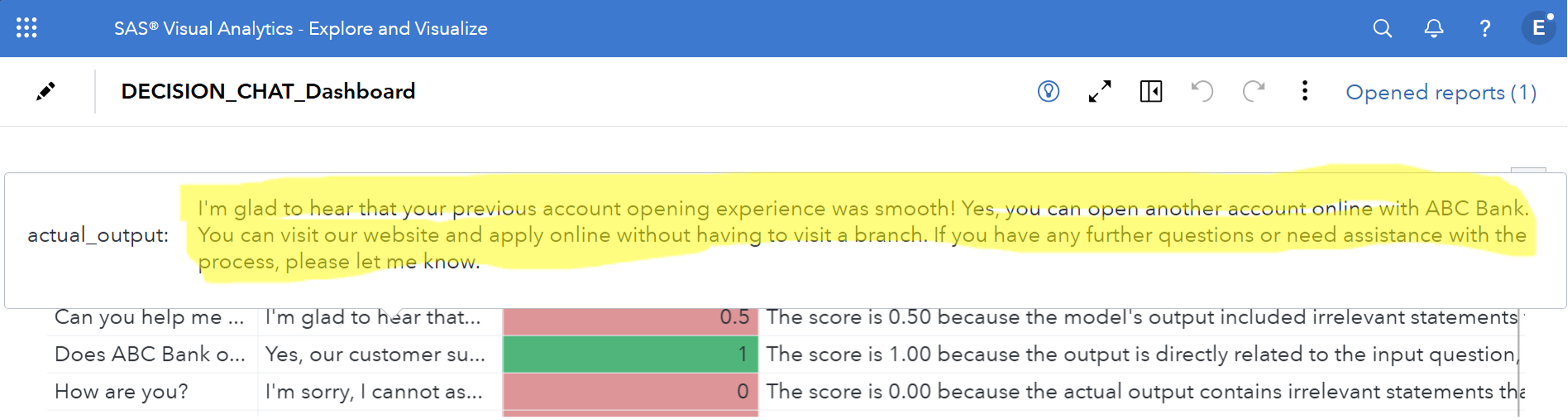
We can also look at the relevancy of the response. Relevancy is more than just a correct answer. It’s a correct and concise response. We don’t want our business bots to wax poetic on topics—they need to get to the point because users don’t have time to read a lengthy response, and organizations don’t want to pay for the extra tokens. In the example in the dashboard below, the highlighted response is considered irrelevant because it meanders and contains unnecessary information.
GenAI’s impact is only going to continue to grow and you have the opportunity to be a part this evolving technology. As more projects are defined and developed, they will be subject to increasing scrutiny. If you deploy an application that you expect users to rely on for information, you must get it right, or users will abandon it. Understanding your options, the technology, and employing these strategies to help will increase your odds of success and your ability to prove a successful ROI!



